

In today’s fast-paced and increasingly interconnected world, businesses rely upon uninterrupted access to data and services. Achieving high availability in networks is essential for ensuring that customers and employees alike have the resources they need, the moment they need them. High availability in networking provides redundant network components and systems to ensure uninterrupted service in the event of a hardware or software failure.
What is high availability?
High availability (HA) is a system design principle that ensures a system can withstand a certain amount of failure and still maintain acceptable levels of performance. In other words, HA systems are designed to keep running even when parts of them fail. Using redundancy and replication, highly available systems ensure that the failure or disruption in a single component does not impact the availability of the entire service.
High availability clusters
High availability clusters, also referred to as failover clusters, are groups of physical machines (hosts) that work together to keep applications running with minimal downtime. By having multiple redundant computers, the clusters are capable of providing uninterrupted service even when individual components or hardware fails. In an HA cluster, all hosts have access to the same shared storage, allowing the virtual machines (VMs) of one host to take over when the VMs on another host fail, this way ensuring continuous uptime.

How does high availability work?
High availability can be implemented in various ways, such as clustering, load balancing, and failover. Clustering involves grouping multiple servers together to provide a single point of access and allows for a single system to take over in the event of a failure. Load balancing involves distributing the load across multiple systems to ensure that no one system is overloaded, while failover is a process that allows a system to switch to a backup system if the primary system fails. HA systems are designed based on three key principles: eliminating single points of failure, reliable crossover, and detection of failures.
Eliminating single points of failure: Having a single point of failure is, by definition, the opposite of a highly available setup (for example, one copy of your application running). So, if any one of those components that are serving a specific role in that network chain fails and goes down, then you've got an outage that is impacting users trying to access the system. Eliminating single points of failure is about identifying where you have those situations in your architecture and making sure that you implement redundancy and plans for handling failure at each one of those points in the system.
Reliable crossover: In the event of a failure, reliable crossover refers to having a seamless cutover from your primary instance or set of instances over to your backup. For example, in a scenario where you have a couple of instances of your application running and instance A goes down, you need to automatically handle the cutover to instance B without any downtime or error messages coming back to the user.
Detection of failures: Failure detection goes hand in hand with reliable crossover and it is, in fact, what drives the crossover mechanism. Failure detection involves setting up health checks on all the copies of your application, allowing you to identify failures in your instances very early on. If, for example, you've got instance A and instance B in your backend load balancing pool, and all of a sudden, instance A stops passing the health checks, by quickly detecting that failure, you can transparently cutover to only routing traffic to instance B, avoiding downtime.
Note: The above scenario, where you have two instances always running, is an active/active high availability design approach — both instances are always active and handling traffic, and traffic is rerouted from one to the other in case of failure. A different approach would be to have an active/passive HA architecture where you have one active instance (instance A) and one passive or inactive instance (instance B). In this scenario, all traffic is handled by instance A while instance B remains on standby until there is a failure in instance A, in which case all traffic gets rerouted to instance B.
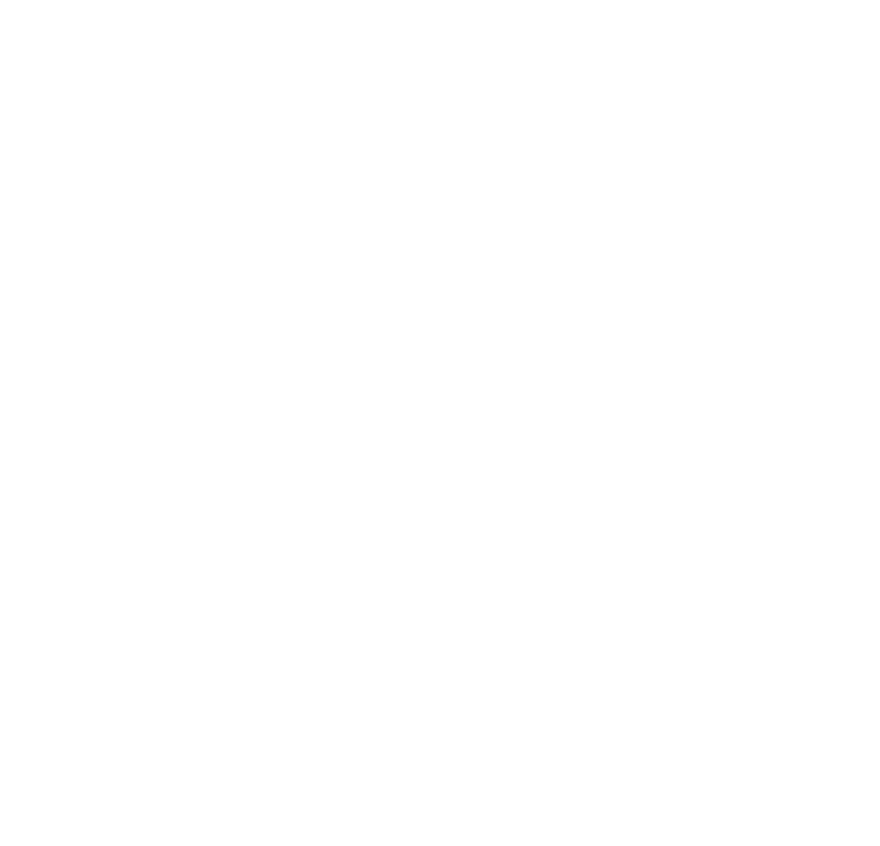
The diagram below presents a basic architecture of an HA system.
High availability vs. fault tolerance
High availability and fault tolerance are two terms that refer to designing systems with the possibility of failures in mind and being able to tolerate such failures and continue operating. Although those two principles are often used interchangeably, there is a nuanced difference between the two. Fault tolerance, in fact, expands on high availability and offers a greater level of protection in case infrastructure components fail. Fault tolerance is essentially a more stringent version of HA, where even less (or no) downtime is expected, however, this usually results in an additional cost due to the increased resilience.
High availability vs. disaster recovery
High availability is a principle that deals with failures at the component level, so that if there's a failure at the component level, it will continue to run and not impact the wider system. Disaster recovery, on the other hand, deals with wider system failures. For example, adopting disaster recovery principles would deal with the scenario of a local data center that disappeared in a natural disaster and you need to figure out how to route your applications around that. In a nutshell, high availability makes sure that there are processes and systems in place to deal with failures in individual components of the system, while disaster recovery makes sure such processes are in place to deal with a failure that would impact a larger portion of the entire system.
How can you achieve high availability?
Now that you have a better understanding of what high availability is, the next step is to understand how you can get there. To achieve high availability for your systems, there are a few steps to keep in mind.
Design systems with HA in mind: When you are initially designing a system, think of all the potential single points of failure, how you can plan around them, and keep them in mind from a technical administration standpoint, as well as plan for the budget of the additional components you will require to eliminate those single points of failure.
Define success parameters: Evaluate the trade-off between the need for uptime versus the cost of running an HA system, by deciding what is an acceptable level of downtime. It is also important to decide ahead of time on the metrics you need to monitor that would define the success of your HA initiative.
Continuous tests of the failover systems: Regularly test the cutover mechanisms you have in place and make sure they are working as intended. You don't want the first time that you're testing a failover to be in an actual failover event!
Continuous monitoring: By continuously monitoring usage metrics and the general load on the system, you get a better understanding of the state and needs of your system, and if you have properly deployed for HA. This understanding can drive decisions on whether or not you need to scale out to additional instances, deploy more copies of your application, etc.
Analyze and evaluate data: That goes hand-in-hand with the previous step and is the direct outcome of continuous monitoring. Make sure you properly analyze the data you collect and take the appropriate actions.
Why is high availability important?
So, why would you go through this technical process? If it is not obvious by now, high availability overall reduces risks in your system. By eliminating single points of failure, and implementing reliable crossover and mechanisms for timely detecting failures, you are drastically reducing the risk of downtime for your application, you are making sure your customer-facing services are reliable and have a high level of uptime. High availability, for example, is crucial for any e-commerce company that wants to make sure their store is always up and running since any downtime has a direct impact on revenue and customer satisfaction.
That being said, it is also important to note that high availability comes with a significant trade-off. HA systems are more complex to create and manage, with several different moving pieces to manage and account for. That complexity comes with management and monetary costs. By definition, a high availability setup has more components running than a simple architecture with a single point of failure. That translates to either additional cloud spend, if you're running something in the cloud, or paying for hardware in a data center.
The balance between the benefits of high availability and the cost and complexity trade-off is the main driver of most discussions around HA. If there was no trade-off to evaluate, every application on the internet would have 100% uptime and would be totally fault tolerant and highly available. However, deciding on whether to adopt HA principles or not becomes an exercise of finding that sweet spot between the need for a sufficient level of uptime and resiliency without taking on unbearable infrastructure and cloud costs.
How can you measure high availability?
Availability is defined as the percentage of the time a system is available to the user and it is calculated using a basic formula that is the ratio of the time the system is expected to be available (uptime) to the total amount of time we are measuring (expected uptime + expected downtime).
There are three key metrics that are commonly used to measure availability effectively.
- Mean Time Between Failures (MTBF): The average time between the point when a system begins normal operation and its next failure.
- Mean Time To Repair/Recovery (MTTR): The period of time when the system is unavailable while the failed component is repaired or returned to service.
- Mean Time to Detection (MTTD): This metric is, in fact, part of MTTR and refers to the amount of time between the moment when the failure occurred and the moment when repair operations began.
If you want to understand better how availability is measured, check out this detailed paper by AWS.
Achieve high availability with Traefik Enterprise
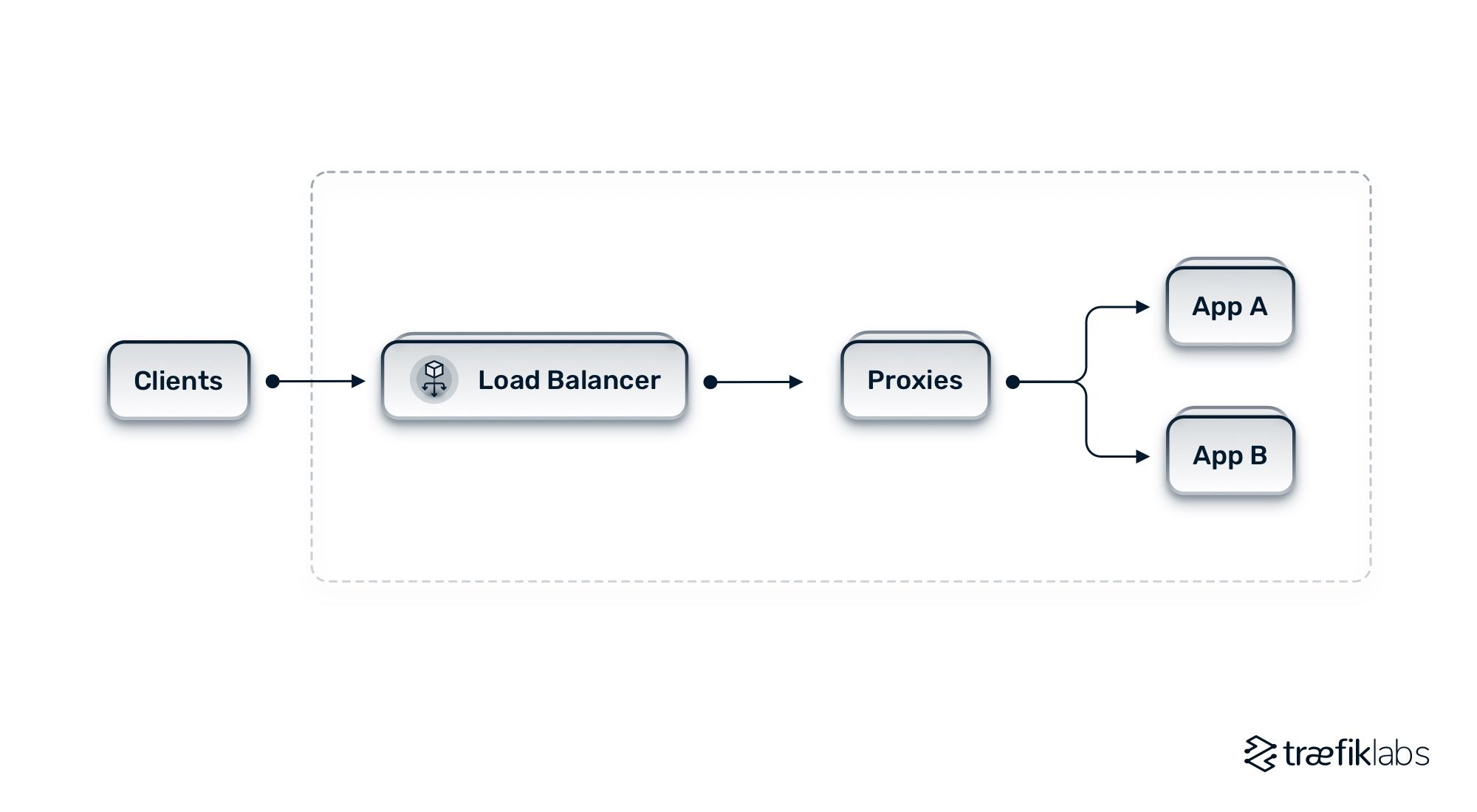
Ensuring an optimal level of uptime means implementing highly available systems at every point of your networking architecture. Traefik Enterprise provides a distributed architecture with multiple ingress proxies that ensure fault tolerance in handling incoming traffic, as well as a highly available control plane.
The diagram below shows the general architecture of Traefik Enterprise and how it applies HA principles.
Interesting in learning more about Traefik Enterprise and how it can help you achieve high availability for all your applications? Don’t hesitate to book a demo or try it out yourself with our 30-day free trial.
References and further reading
- Load Balancing 101: Network vs. Application and Everything You Wanted to Know
- Load Balancing High Availability Clusters in Bare Metal Environments with Traefik Proxy
- Load Balancing High-Availability Clusters with Traefik
- 9 Best Practices for Designing Microservice Architectures
- Unlock the Power of API Gateways in your Enterprise
- Availability and Beyond: Understanding and Improving the Resilience of Distributed Systems on AWS