Who's in Charge? The Shared Responsibility Model for API and AI/ML Model Versioning


Your ML model just broke in production. Was it the API? The model? Or the versioning gap between them?
As organizations scale their AI operations, the traditional approach of handling versioning at a single layer is breaking down. This limitation has led forward-thinking enterprises to adopt what we call the "Shared Responsibility Model" for versioning, distributing responsibilities between API management platforms and ML serving platforms.
The Growing Complexity of AI at Scale
As machine learning transitions from experimental projects to business-critical applications, organizations face increasing complexity in managing both the APIs exposing AI capabilities and the underlying ML models themselves. Effectively deploying and managing these solutions isn't just a data science puzzle; it's a complex challenge involving engineering, IT operations, and business strategy, with Deloitte noting that getting AI into production remains difficult[¹]. This challenge stems from the unique dual nature of ML systems: they are both software services defined by API contracts and statistical models requiring frequent updates, each with distinct lifecycle requirements.
Getting this right extends far beyond technical elegance; it directly impacts customer experience, operational efficiency, and the ability to innovate rapidly in an increasingly AI-driven marketplace.
With 78% of organizations reporting AI use in 2024, up significantly from 55% the previous year, the need for effective versioning strategies has never been more critical.
The Scale and API Management Challenge
One major factor amplifying this complexity is the sheer proliferation of AI models. Platforms like Hugging Face now host over 1.4 million model repositories (as of April 2025), reflecting an explosion of options available for teams to test and deploy. This rapid expansion underscores the versioning challenge.
It also leads directly to a critical related insight: The more AI you deploy at scale, the more APIs you have. And that creates an API management problem. We're witnessing a "Cambrian explosion" of AI APIs, as organizations increasingly expose AI capabilities as modular services. Managing this API sprawl, including shadow APIs created outside governance, is crucial; failing to do so can thwart AI initiatives due to data issues, security risks, and integration failures. Furthermore, AI APIs present unique management needs around aspects like token-based rate limiting, prompt handling, and multi-model routing.
The Shared Responsibility Model Explained
The Shared Responsibility Model distinguishes between client-facing API contracts and underlying model implementations, creating a clear boundary of concerns that addresses the unique challenges of AI systems at scale.
API Management Layer Responsibilities:
- Contract Stability: Maintains consistent interfaces that clients can rely on regardless of backend changes
- Access Control & Security: Implements authentication, authorization, and data protection at the API boundary
- Traffic Management: Handles rate limiting, throttling, and request distribution
- Observability: Provides API-level metrics, logging, and monitoring
- Documentation & Developer Experience: Offers consistent, up-to-date API specifications and documentation
- Versioning Strategy: Manages API versions and deprecation policies
ML Serving Layer Responsibilities:
- Model Lifecycle Management: Handles model training, validation, deployment, and retirement
- Model-Specific Versioning: Manages rapid iteration of model weights, architectures, and parameters
- Inferencing Infrastructure: Optimizes compute resources for model serving
- Model Monitoring: Tracks performance, accuracy, and cost metrics
- Canary Deployments: Implements gradual rollout of new model versions with automated rollback
- Feature Management: Maintains repositories of model input variables (features) and ensures consistent transformations across training and serving
By clearly delineating these responsibilities, organizations can achieve a balance between stability and innovation. The API layer provides a consistent contract that shields consumers from the complexity and frequent changes occurring in the ML layer, while the ML layer retains the flexibility needed for rapid experimentation and improvement. This separation of concerns allows each layer to follow its own appropriate versioning cadence and practices.
Bridging MLOps and APIOps for End-to-End Scalability
Effectively managing the ML layer requires robust MLOps practices. However, since most AI/ML capabilities are consumed via APIs, focusing only on model lifecycle management isn't enough for true scalability. This is where APIOps becomes essential – applying DevOps principles to the entire API lifecycle (design, development, testing, deployment, monitoring, retirement)[²].
The relationship between these two operational domains is crucial:
- MLOps focuses on model development, training, and deployment
- APIOps manages how these models are exposed to consumers
These systems must work in harmony. Even the most efficient MLOps pipeline will create bottlenecks if your API management can't keep pace. When your data science team develops a new fraud detection model version, the API exposing that capability must be ready to handle the change without disrupting consumers.
As AI adoption accelerates, the number of AI-powered APIs within an organization multiplies rapidly. Without robust APIOps practices ensuring consistency and automation in API management, you won't realize the full agility benefits promised by your MLOps investments.
The Kubernetes-Native Advantage: Bridging API and Model Versioning
Kubernetes provides the ideal foundation for implementing the Shared Responsibility Model and coordinating MLOps and APIOps in practice. Its declarative nature, robust service discovery, and native resource definitions allow different specialized tools to manage their respective layers while integrating seamlessly. Here's how it bridges API and ML model versioning:
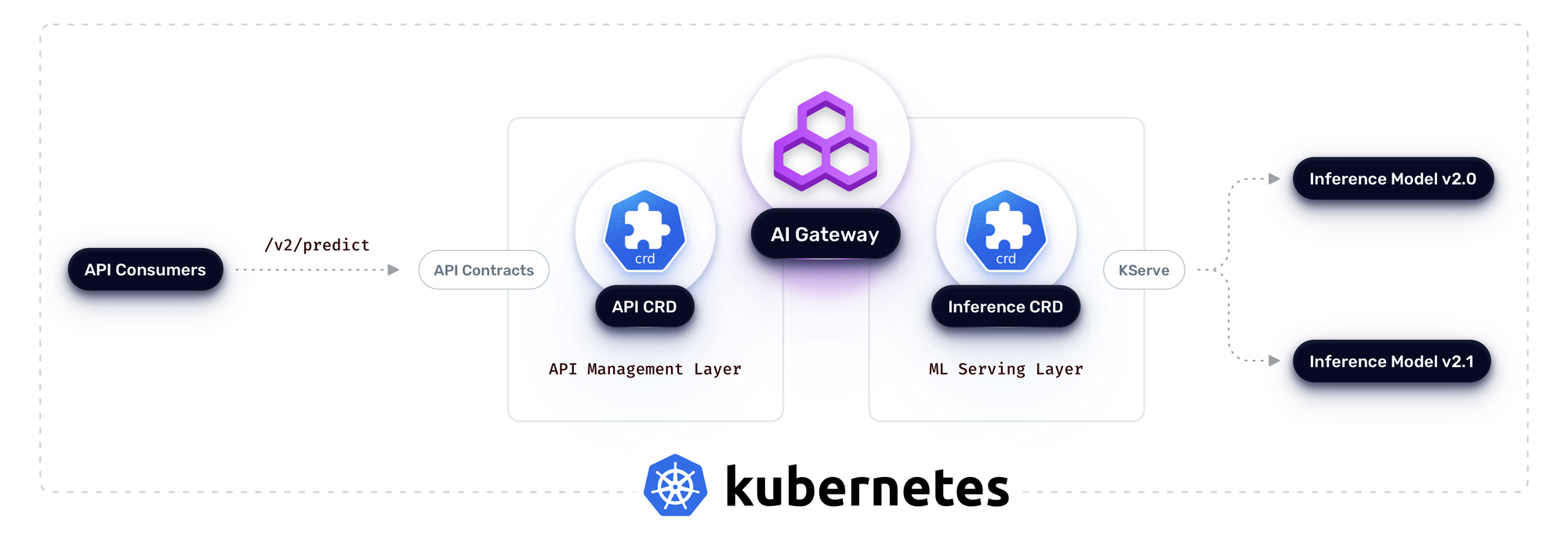
API Versioning (The Contract): An API management platform like Traefik Hub leverages Kubernetes Gateway API or Ingress resources to define and manage the stable API contracts exposed to consumers. It can handle different API versions concurrently – for example, routing requests based on the URL path (/v1/predict vs. /v2/predict), headers (API-Version: 1 vs. API-Version: 2), or more. Each API version defined in the gateway routes to a specific, stable Kubernetes Service name. This ensures clients always interact with a consistent API contract, regardless of the underlying model changes, aligning with standard API versioning techniques documented for platforms like Traefik Hub.
ML Model Versioning (The Implementation): Behind that stable Kubernetes Service endpoint managed by the API gateway, an ML serving platform like KServe manages the actual model deployments using its own Custom Resource Definitions (CRDs), such as the InferenceService. When a new ML model version needs to be rolled out (e.g., fraud-detection-v2.1 replacing v2.0), KServe can manage this transparently to the API consumer. Using its CRD, you can specify that only a small percentage of traffic (e.g., 10% via the canaryTrafficPercent field) should initially hit the new model version (v2.1), while the stable v2.0 handles the rest. KServe manages this traffic splitting internally through its integration with Kubernetes networking capabilities.
The AI Gateway Advantage: Between the API Management and ML Serving layers, a specialized AI Gateway addresses unique challenges of AI-specific workloads. Traefik's AI Gateway provides crucial capabilities that enhance security, performance, and governance—ranging from semantic caching that optimizes response times to content protection that ensures compliance. This middle layer bridges the gap between stable API contracts and dynamic model implementations, providing AI-specific optimizations that neither the API layer nor the ML layer can deliver alone.
Connecting Theory to Practice: This demonstrates the Shared Responsibility Model in action on Kubernetes. Traefik Hub handles the external API contract and its versions (/v1, /v2), directing traffic to the appropriate stable backend service endpoint. The AI Gateway provides critical AI-specific optimizations and protections, while KServe manages the ML model versions served by that endpoint, handling canary rollouts (v2.0 vs. v2.1) without disrupting the API contract defined by the Traefik Hub API Management layer. Kubernetes acts as the orchestration layer, enabling these specialized tools to manage their respective responsibilities cohesively.
Business Impact: Why This Matters
Getting this layered, Kubernetes-native approach right directly impacts the bottom line:
Faster Time-to-Value: By separating concerns and streamlining workflows across both MLOps and APIOps, businesses can significantly accelerate innovation. AI, managed effectively, can cut product development timelines by up to 50%, while MLOps practices can slash model deployment times by 30-50%[³], allowing faster response to market needs.
Enhanced Efficiency & Productivity: CEOs are already seeing tangible results, with 56% reporting efficiency gains from GenAI. Organizations effectively leveraging AI can achieve significantly higher productivity growth.
Improved Stability & Trust: The model allows underlying AI capabilities to be updated without breaking crucial client integrations or compromising backward compatibility. Robust management also helps mitigate risks associated with AI, such as inaccuracy and security vulnerabilities.
Future-Proofing Your AI Strategy
The convergence of API management and AI delivery is fundamentally reshaping how organizations innovate and compete. Successfully scaling AI requires more than just adopting algorithms; it demands a strategic approach to managing the interplay between APIs and models. Adopting a clear strategy like the Shared Responsibility Model is essential for navigating this complexity and unlocking the full potential of your AI investments.
This is where Traefik Hub, as a Kubernetes-native API management solution, plays a pivotal role. Built for the modern stack, it provides the sophisticated routing, security, governance, and visibility needed to expertly manage the crucial API management layer – facilitating the robust APIOps practices required to govern the "Cambrian explosion" of AI APIs within your Kubernetes environment.
The inclusion of specialized AI Gateway capabilities extends this value proposition further:
Semantic Caching: Unlock Scalable, Cost-Effective AI: When AI systems scale from experimentation to production, computational costs and latency can become major hurdles. Traditional caching methods often fall short, especially for resource-heavy large language models. Traefik's AI Gateway addresses these challenges with Semantic Caching, which uses advanced embedding techniques to understand the meaning behind queries, enabling intelligent reuse of results for similar requests.
This approach delivers tangible benefits:
- Dramatically reduces response times from seconds to milliseconds for semantically similar queries
- Eliminates redundant, costly computations for common request patterns
- Optimizes resource allocation by serving cached responses for similar queries while dedicating computing power to truly novel requests
- Integrates seamlessly with popular vector databases in cloud-native environments
Content Guard: Enabling Secure, Compliant AI: As AI powers increasingly critical business functions, ensuring proper governance becomes essential. Content Guard provides superior protection by safeguarding sensitive data and ensuring both inputs and outputs meet ethical and regulatory standards. Unlike basic solutions, it leverages contextual natural language processing for highly accurate detection across data types.
With over 35 predefined PII recognizers and customizable rules, Content Guard ensures:
- Comprehensive detection and de-identification of sensitive information
- Consistent policy enforcement across distributed AI deployments
- Compliance with evolving regulatory requirements
- A foundation for responsible AI that builds user trust
Together, these capabilities empower platform teams to provide stable, secure access while ML and application teams innovate rapidly behind the scenes using MLOps.
Taking Action: Next Steps for Your Organization
How is your organization preparing for the operational realities of scaling AI? Here are three concrete steps you can take today:
- Assess Your Current State: Evaluate your existing API management and ML serving capabilities against the Shared Responsibility Model. Identify gaps in your versioning strategy that could impede AI scaling.
- Build Cross-Functional Alignment: Bring together your API platform teams and ML engineering teams to establish clear boundaries of responsibility and collaborative workflows.
- Implement a Pilot Project: Select a non-critical AI service and implement the Shared Responsibility Model using Kubernetes-native tools. Document learnings and establish patterns that can be scaled across your organization.
Ready to learn more? Contact the Traefik sales team for a personalized consultation on how the Shared Responsibility Model can be implemented in your organization using Traefik Hub.
Ultimately, embracing the Shared Responsibility Model, implemented through coordinated MLOps and APIOps practices, fosters better collaboration across diverse teams – engineering, operations, data science, and business – creating a scalable and resilient foundation for delivering AI-driven value. Investing in the right operational architecture today, with robust API management at its core, is investing in your organization's agility and innovation velocity for tomorrow.
References
[¹] Deloitte. "AI in Enterprise Applications: Challenges and Opportunities." https://www2.deloitte.com/us/en/insights/focus/signals-for-strategists/ai-in-enterprise-applications.html
[²] Microsoft Learn. "API Design Best Practices." https://learn.microsoft.com/en-us/azure/architecture/microservices/design/api-design
[³] Cogent Infotech. "MLOps Benefits: Deployment Time." https://www.cogentinfo.com/blog/mlops-benefits-deployment-time/







